Tablestore发布Timeline 2.0模型 亿级消息系统的核心存储与信息处理新纪元
在数字化浪潮席卷全球的今天,高效、可靠地处理海量实时信息已成为众多互联网应用与服务的生命线。无论是社交媒体的动态推送、在线协同的即时消息,还是物联网设备的海量数据流,背后都需要一个强大的核心存储系统作为支撑。阿里云Tablestore正式发布了其Timeline 2.0模型,标志着面向亿级消息系统的信息处理与存储支持服务迈入了全新的发展阶段。
一、 核心挑战:亿级消息系统的存储之困
传统的消息系统在应对亿级甚至更高量级的消息吞吐时,常常面临严峻挑战。这些挑战主要体现在:
- 海量数据存储与低延迟访问的矛盾:需要同时保存庞大的历史消息数据,并保证最新消息的极低延迟读取。
- 高并发写入与读取的稳定性:在高峰期,每秒可能需要处理数百万条消息的写入和读取请求,系统必须保持稳定。
- 灵活的数据模型与查询需求:消息类型多样(文本、图片、状态等),查询模式复杂(按会话、按时间范围、条件过滤等)。
- 成本与效率的平衡:在满足性能要求的需尽可能降低存储与计算成本。
二、 Timeline 2.0模型:架构与核心创新
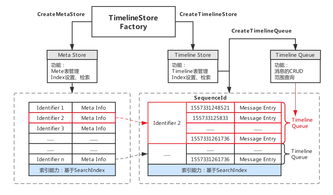
Tablestore Timeline模型最初便是为消息、动态流等场景设计的抽象数据模型。Timeline 2.0在其基础上进行了深度演进和增强,旨在成为亿级消息系统的“脊柱”。
1. 分层存储架构
Timeline 2.0创新性地采用了智能分层存储设计。
- 热存储层:基于Tablestore高性能表格存储,承载最近期的活跃数据。该层针对低延迟、高吞吐的读写操作进行了极致优化,确保用户获取最新消息的体验丝滑流畅。
- 冷存储层:无缝对接对象存储OSS,用于存储全量的历史消息数据。这种设计实现了成本的显著优化,同时保证了数据的持久性和可访问性。
系统会自动或根据策略将数据从热层沉降到冷层,对上层应用透明。
2. 统一的数据模型与丰富的索引
模型将一条消息(或一个动态)抽象为一个带有多属性(如消息ID、时间戳、发送者、接收者、内容、扩展属性等)的“事件”。Timeline 2.0提供了更强大的内置索引能力:
- 主键索引:保证消息的唯一性与顺序性(如
(ConversationID, SequenceID))。 - 二级索引:支持按多种维度(如发送者、时间范围、标签)进行高效查询,满足了消息系统复杂的检索需求,避免了应用层繁琐的拆表和管理工作。
3. 极致优化的读写链路
- 写入:支持海量客户端的高并发、顺序写入,保证全局顺序和极高吞吐。
- 同步读取:针对拉取最新消息或特定范围消息,提供毫秒级延迟的查询能力。
- 增量订阅:提供了高效的增量数据拉取通道(类似CDC),便于下游进行实时计算、分析或同步,构建流处理生态。
4. 增强的生态集成与可观测性
Timeline 2.0与阿里云生态系统,特别是实时计算Flink、大数据分析等服务的集成更为紧密。提供了更完善的可观测性指标,如写入延迟、消费延迟、存储量等,方便运维和诊断。
三、 应用场景:不止于即时通讯
Timeline 2.0的发布,使其应用边界从传统的即时通讯、社交动态流,扩展到更广阔的领域:
- 大型在线协作平台:如文档协同编辑的历史版本流、评论与@消息流。
- 物联网IoT平台:海量设备上报的状态时序消息流与事件流。
- 互动直播与游戏:弹幕消息、全局广播、玩家状态同步。
- 金融交易与风控:高并发订单流、交易日志的实时存储与查询。
- 服务端审计与日志:分布式系统操作日志的集中存储与回溯。
四、 核心价值:为开发者降本增效
Tablestore Timeline 2.0模型的最终价值,在于为企业和开发者提供了一个 “开箱即用” 的亿级消息系统核心存储解决方案:
- 简化开发:无需从零自研分库分表、索引维护、冷热分离等复杂架构,聚焦业务逻辑。
- 保障稳定:基于阿里云久经考验的底层基础设施,提供高可用、高可靠、强一致的服务保障。
- 弹性伸缩:存储与计算能力可随业务需求无缝扩展,无需提前规划容量。
- 总体成本最优:通过智能分层存储,在保证性能的前提下,大幅降低长期数据存储成本。
###
信息的实时流动是数字世界的脉搏。Tablestore Timeline 2.0模型的发布,正是为了更强劲、更稳健地驱动这一脉搏。它通过架构创新和技术深化,将海量信息处理和存储的复杂性封装起来,为构建下一代高并发、大数据量的实时应用提供了坚实可靠的基石。对于正在或即将面临亿级消息处理挑战的团队而言,这无疑是一个值得重点关注和评估的技术选择。信息处理的正朝着更实时、更智能、更经济的方向演进,而Timeline 2.0已然在这一道路上树立了新的标杆。
如若转载,请注明出处:http://www.iotloader.com/product/34.html
更新时间:2026-06-18 09:54:32